记一次生产事故排查
某天晚上,技术vp突然在管理群里说,官网名单预约注册接口可能有问题,通过复盘上次到生产故障,在捞nginx日志到时候,发现很多通讯失败的,也就是说nginx的access.log中记录了很多http 的response code 是非200的请求。
如下是整体的排查过程(转发):
时间点:7月9号
从access.log 中发现一些状态码 为499 请求,且rquest_time 大部分60s。与业务方确认用户预约接口(/api/student/xxx)相关流程, 通过请求body 获取用户预约手机号,抽查20条数据排查, 2条在数据库中找不到相关记录,其它18条数据大部分请求失败前几分钟已写入数据库。
Nginx 499解释:
代表服务端请求还未返回时客户端主动断开连接;还有一种情况就是有人攻击,故意消耗服务端资源。
用户请求链路: 用户-> waf -> LB -> nginx -> pm2 -> nodejs
1、有人攻击?
从修改nginx配置proxy_ignore_client_abort on 出现504状态码: Nginx-> pm2-> nodejs 内部请求排除被攻击的可能性
2、客户端主动断开?
Case : Nginx 499 ,rquest_time 60s:
思考1:
Nginx 后端 -> pm2接口请求60s没返回结果,导致用户/waf/LB某个端主动断开上层server 请求,导致LB 断开 nginx 连接,nginx记录499,依次将http code 499返回给LB/waf 。
修改nginx 配置:proxy_ignore_client_abort on (客户端主动断开以后,nginx会等待后端服务器处理完成或者超时)
从如下截图可以看出,nginx返回状态码504,超时rquest_time 60s,这个时候可以确认应该是nginx -> pm2 -> nodejs 这段数据处理存在问题。
从nginx随机塞选出几条请求状态码504 ,超时rquest_time 60s的请求。
但pm2 access log中并未找到相应记录。Nginx –> pm2 网络通信存在问题?
第一个猜测:
我们选择504报错比较多的机器,大概2分钟左右会出现一个504, 尝试通过抓包分析
sudo tcpdump -i lo host 127.0.0.1 and port 8085 -w xxx.cap ( -i lo 抓取回环网卡进出的包, host 127.0.0.1 本机,port 8085 pm2端口 ,-w xxx.cap 保存为cap文件,方便使用wireshark打开分析)
通过wireshark打开以后,出现有tcp retransmission 异常的包,如下图: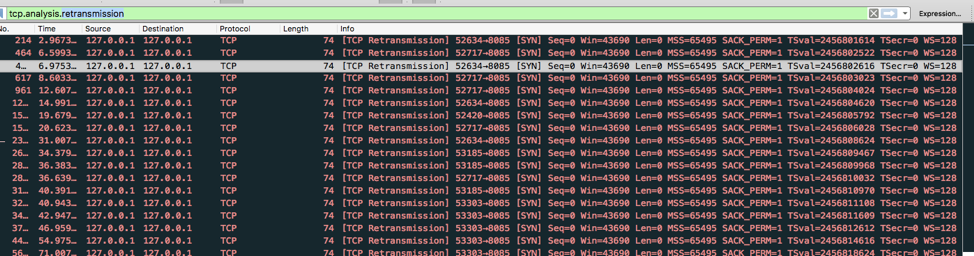
我们选取nginx->pm2的某一个请求分析,如下图可以看到发送第一个SYN包的时间是2019-07-10 14:20:31,重试6次tcp syn包后放弃。
为什么是6次? tcp_syn_retries参数:对于一个新建连接,内核要发送多少个 SYN 连接请求才决定放弃,图二我们可以看到参数retry6次放弃连接。
如图三:我们查找2019-07-10 14:20:31 + 60s = 2019-07-10 14:21:31
与nginx access log 超时时间吻合
(图一)
(图二)
(图三)
思考1:
由上面可以看出tcp syn 包重传发送失败,SYN queue队列满?导致Nginx->pm2超时。8085端口为pm2 服务端口,backlog 设置 128 , 80/443 端口分别为http/https 端口。

如果SYN queue满导致的问题,SYNs packets drop会不断增加, 但间隔一段时间获取SYNs drop 值,并未发现数量增加。
貌似失去排查方向了, 运维同事提醒可能由操作系统内核导致的bug,于是搜素ubuntu xxx TCP retransmit , https://askubuntu.com/questions/475700/application-stuck-in-tcp-retransmit
看到这篇文章我们是很惊喜的,因为Linux kernel 3.13 (Ubuntu 14.04) on Virtual Machines
都符合我们要求, 于是尝试调整MTU,net.ipv4.tcp_sack参数,并未得到解决。
貌似又失去了方向,nginx -> Pm2 有问题, 那么是系统导致的问题, 还是pm2 bug 导致的问题?我们尝试一步步验证。
写了个golang client/server demo代码,nodejs demo server ,测试方向如下(都是在问题机器上测试)
1、golang client(开5个协程)向 golang server 不断的连接(连接出错抛error),写,关闭 。 (下图可以看出,我们跑了接近500w次,未出现错误)
2、golang client(开5个协程)向 nodejs server不断的连接(连接出错抛error),写,关闭 。 (下图可以看出,我们跑了接近500w次,未出现错误)
3、golang client(开5个协程)向 pm2 server不断的连接(连接出错抛error),写,关闭 。 (下图可以看出,我们跑了不到2k次,都出现错误)

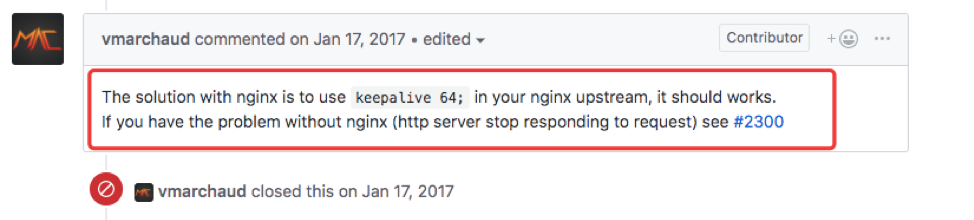
这个时候比较明朗了, 定位到应该是pm2 或者pm2-> nodejs导致的问题 , 于是我们尝试到github pm2 issue中去寻找bug ,有人与我们遇到相同的问题, 于是我们尝试如下解决方案,通过修改nginx->pm2 加上keepalive 64 解决问题。 https://github.com/Unitech/pm2/issues/1484
具体导致原因,我们后续深入分析。
本文作者 : braveheart
原文链接 : https://zhangjun075.github.io/passages/记一次生产事故排查/
版权声明 : 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
知识 & 情怀 | 二者兼得

